After the AWS London Summit I joined the first virtual race: The London Loop. I must admit that I didn't write during that time because it was very competitive and I have spend a lot of time trying to keep up with the race. When you don't know what you're doing or supposed to do, you tend to do a lot of pointless stuff and this requires a lot of effort.
Virtual races
Joining the physical races is difficult from the logistics point of view - not all can come to a summit, and there is a finite amount of tracks. To overcome this issue Amazon have organised a series of six virtual races with The London Loop being the first one.
The initial steps are similar:
- prepare a reward function
- train a model
What changes however is what you then do with the model: instead of downloading and loading onto a car, you submit the model to a virtual race. It's as easy as clicking two buttons.
A submission to a virtual race is almost like running an evaluation in the AWS DeepRacer Console. Almost, because the race evaluation is happening in a separate account and the outcome is fed back to you through the race page through information about the outcome of evaluation.
The information can be:
- Under evaluation - still verifying
- No status - not a single lap completed
- Unable to finish two laps - and a single lap result provided
- Successfully completed two laps - and an average time of those
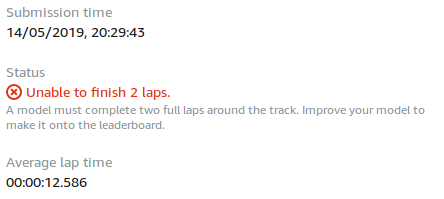
It isn't clear to me whether the fastest laps are taken into consideration, whether they are any two of five laps attempted or consecutive ones, whether the car can get off track during evaluation, whether the car is reset between the laps. Frankly, I haven't spent much time trying to understand it.
There is one more thing that you get - in CloudWatch another group of logs is created with the outcomes of evaluations. This makes the log-analysis handbook even more useful than before - all of the utilities provided for evaluating the model apply to race submissions as well.
The output of print function in the reward function is also stored in CloudWatch which provides some functionality to analyse the logs. It comes handy when I don't have the time to start the Jupyter Notebook for analysis
Unfortunately there is no information in the logs to detect which model the evaluation used. For now I recommend making notes on what model you are evaluating when - dates should be sufficient to map models to logs. I may be spending some time to make this simpler.
The London Loop
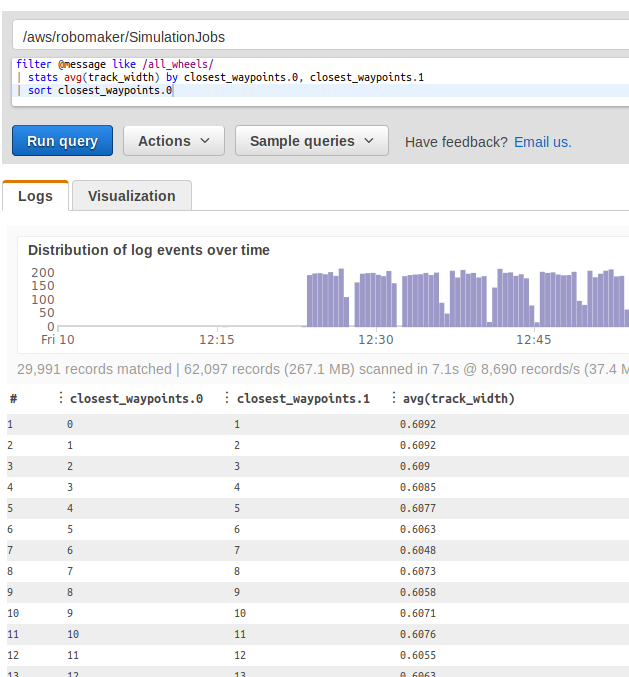
The track is 19.45 meters long, has some sligthtly shorter straight lines and turns of various shapes and sequences. It is defined with over 200 waypoints, the track's width is 59-61 cm.
In Robomaker simulation the textures on the track are noisier than the ones in re:Invent track. Also, there is a sky and bumps around the track. The bumps usually hold the car on the texture, although I have seen a car drive off and fall into the void twice. Awesome view.
Because we didn't initially receive a waypoints file for the London Loop I decide to prepare a script to calculate them. I extracted the waypoints through the reward function, then I checked the width of the track in detail:
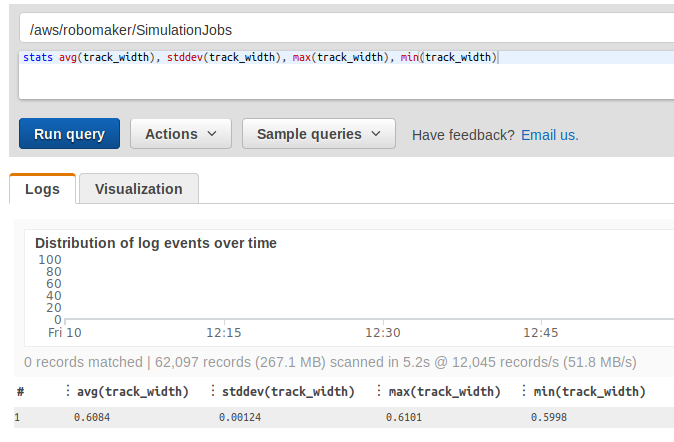
Since the difference between the most narrow and the most wide spot is around 1 centimeter, I decided to simply assume 60 cm width. Then I went along the waypoints and calculated a line ortogonal to a central points line and crossing it on a given waypoint. Finally, I calculated points on this line, located 30 cm from the central point. Having those three points (or six coordinates), I stored them in a list with six numbers in each element:
[center line x axis, center line y axis, inner border x axis, inner border y axis, outer border x axis, outer border y axis]
The outcome of this calculation is then saved to an npy file and can be loaded in the log analysis tool.
Training
I started analysing the track, looking for the best potential behaviour. I assumed two things:
- I should only train for top speed 5 m/s
- I should find a perfect line on the track for the car to follow
I used the same code to analyse the track and to detect the turns.
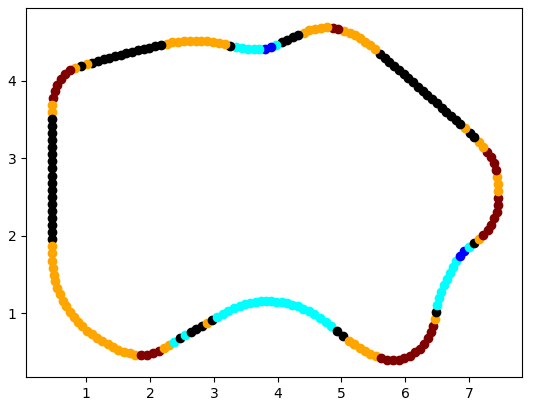
Different colours provide different information about what characteristics given point has. Black means straight line.
While this worked, there was some worry to I had about it:
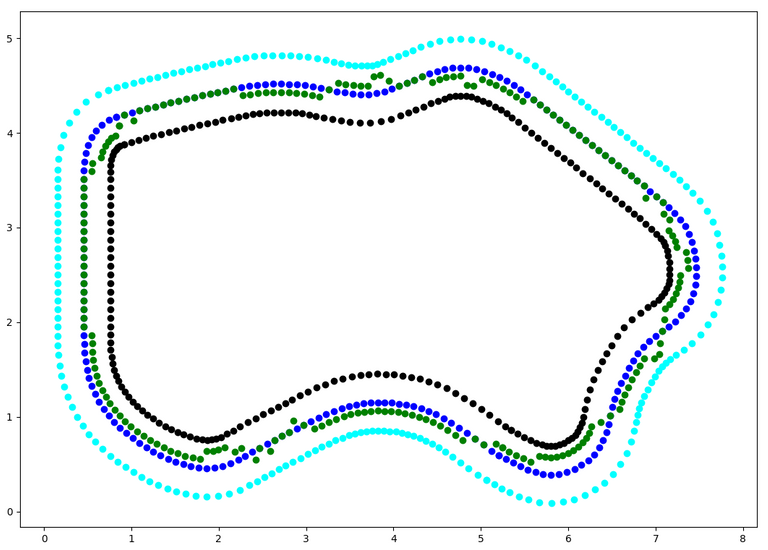
What I did was move the desired line from middle to a side of the track. That's not very precise and the car would suddenly jump into worse rewards, or better. Since I wasn't sure if this would be good or wrong, but felt it could be better, I started reading about the apex and late apex and other details about the racing but could work out the maths, really.
After a couple attempts to calculate the line I decided to sketch it on the track, then check the right points coordinates and feed them into my model to calculate the distance of the car from the line and to calculate the reward based on this. Just note that this is just my gut feeling line that could've been wrong. It wasn't ideal for sure.
Once I did this, I put the points into the code, then interpolated points between them along the waypoints which came out pretty well, but I couldn't get the car to follow the line.

Or should I say: The car decided that the best decision is to turn right, always.
I've spent a lot of time trying to understand why it didn't work and ended up creating this graph:
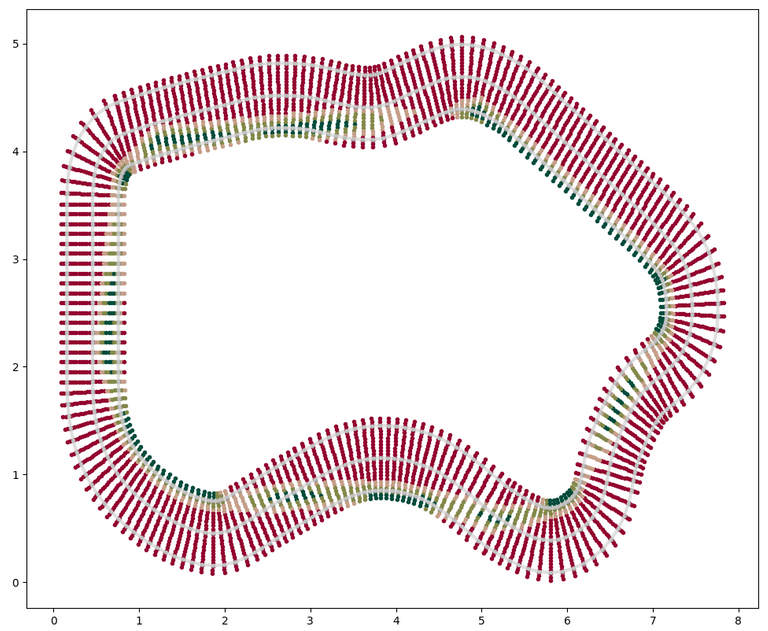
For each waypoint I have taken a number of points along the whole track width and calculated my reward function for them. The colours show different rewards with grey being low and red negative. Also, the reward was calculated in discrete values - for any location located within a given range from the ideal point the value was the same. I could have had ranges like:
- 0-3 cm from the ideal line: 10 points
- 3-10 cm from the ideal line: 4 points
- 10-20 cm from the ideal line: 1 point
- more than 20 cm from the ideal line or off the track: -5 points
In reality some 80% of the track was just -5 and wide areas gave no good suggestion to understand which behaviour is right. If I understand properly, this is known as a problem of sparse rewards.
No wonder the car was going off the track all the time - there were areas on track where highest reward wasn't possible, or even only negative reward was given. Some more maths (proper this time) made the graph look like this:
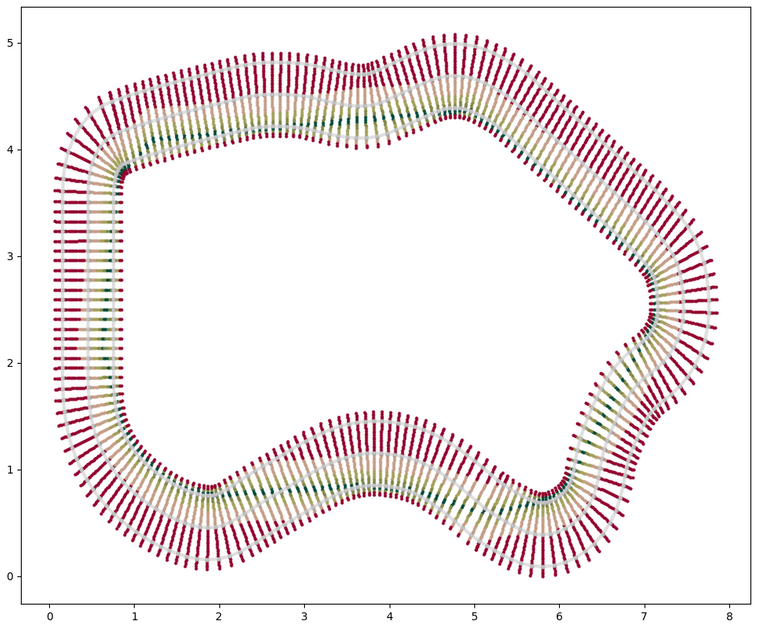
One more improvement was that I introduced gradients, so instead of discrete rewards, I provided a linear function which ascended or descended with different steepnes based on the location on the track.
I went back to training. Shortly after I was able to complete the lap and even jump into fifth. I like fifth. I also liked my time: 12.522s.
Unfortunately I couldn't repeat it. Training showed no progress and I was getting more and more upset with it. What was I doing wrong? I tried a tighter line which made things even worse as half of the trainings would land out of the track and the car would behave even worse.
This was the time when I started looking more into the log-analysis notebook. It was extremely helpful in that it gave me a chance to do initial analysis and plotting. I spent a lot of time reading about pandas and pyplot and analysing the data. It also let me come to conclusion that it was hardly possible to get the time that I got and that most of my models were slightly above average.
In the end I decided to change my reward function completely, ditch the line and attempt to reward behaviours that could lead to good times as a final outcome, but without determining which ones they were. While I managed to work out a new reward function and then the outage happened. Folks at ROS (the tool used for robotics and used in RoboMaker) have detected a security problem which meant someone could have rebuilt and signed their releases with their private key. AWS did the responsible thing of taking access to RoboMaker until the releases were rebuilt and verified. This meant two things:
- I can get some sleep
- I cannot train
In the end I was just falling in the standings until I finished in 20th. 20th out of 860 is pretty decent, but I knew I had to do better going forward, and do it smarter.
The general problem with the race was that the same track was being used for both training and evaluation. This is prone to a problem known as overfitting. My understanding is that overfitting means an object using the model will behave as instructed in one environment, but will fail in others. While one should not do it like this, having a single track to be evaluated against meant it was still worth doing it. But at the same time the model would really really struggle to train away from it when applying improvements so it's worth knowing that this is a bad practice.
What's next
The second race has already started. Kumo Torakku is Japanese for Cloud-shaped truck (I heard). The track introduces new challenges:
- a number of tight, irregular turns
- a couple long straights
- the evaluation track is different from the training one
I have spent around 13 hours training so far which let me achieve a time of 15.1 s and at the moment of writing 24th place. I'm pretty happy with the result for such a short time and am pretty sure I achieved it thanks to extensive analysis. I have an improved reward function, but currently am not training at all because of the costs.
The costs
One thing that he costing example isn't showing is the cost of running a VPC service. There isn't even an attempt to etimate them for the training. This makes the costs quite significantly higher than the declared $3 an hour. What is more, a change got applied recently that increses the number of steps to match the real car's camera's frequency, around 15 frames per second. This has increased the costs above what I am ready or willing to pay.
While support is not yet sure what to do about the charges, we are aware that the AWS DeepRacer team is analysing the costs situation, so we are hopeful that this is just an early stage hiccup. In the meantime I'm making sure my wife receives enough attention and my kids have me.
TODOs
I spent a lot of time working with log-analysis tool provided by the AWS engineers. As a result, I was able to prepare an extension to it which based on the logs provided will reevaluate a reward function for a given training. I was able to apply a different reward function and make sure that the misbehaving runs would get lower rewards and better behaving ones would get higher ones. It is extremely helpful to do that to understand the behaviour of your reward function on step by step basis. So far it is half-finished. I provided it to people in our community as an Early Access Preview. The response was reasonably positive, so I will clean it up a little and prepare a Pull Request for the training tools.
One more thing that I want to do is attempt to prepare a local training environment. There have been some successful attempts in the community already. I will be evaluating whether I can use it without frying my laptop and whether I could use some extra tools to make it more robust. I'm thinking about something with a reasonable GPU, especially since I intend to learn ML from the beginning.
Bragging zone
I am very pleased to learn that AWS DeepRacer Team have shared my article about the log analysis on the AWS DeepRacer Pit Stop page. Steemit link Codelikeamother.uk link
The Community
I am very thankful to Lyndon Leggate for setting up an online community. We are a lovely bunch of people from all over the world, both experienced and novice, learning as we go. While AWS DeepRacer League is a competition with a reward that everyone would like to get, I find it incredible that so many people contribute their time, knowledge, experience and tools for others to benefit from. I somehow value the ability to contribute to the community over the urge to get into top 18 point scorers. I love it when people from various countries meet in person at Summits after having met in our group.
If you would like to join the community, here is the link: Click
